
In this post, I’m especially happy to dive into my paper “User-Driven Adaptive CSI Feedback With Ordered Vector Quantization,” which was published in the IEEE Wireless Communications Letters in 2023 (Rizzello et al., 2023). We’ll explore the problem that inspired our research, the key solution we proposed, and the results we found.
So, what’s this about?
At its core, the paper is all about compressing something called Channel State Information, or CSI. Think of CSI as a detailed map that tells us exactly how a wireless signal travels between a phone and a cell tower, including all the obstacles, reflections, and all the little things that affect your connection.
Why would we need to compress it?
Well, that’s the big question! Sharing this “map” is incredibly useful for a system to work efficiently. However, the map is huge! Sending all that information takes up a lot of valuable bandwidth. So, the motivation for this work is simple: we’re trying to save precious bits during transmission. ![]()
The big challenge in details
In frequency division duplex systems 1, the base station (that’s the big tower) doesn’t automatically know the “CSI map” of how signals get to your phone. It has to ask you for it! This creates a constant feedback loop:
- The tower sends a reference signal.
- Your phone receives it and estimates the CSI.
- Your phone then sends that CSI back to the tower.
However, as we build bigger, more powerful towers with more antennas (massive MIMO), the size of that map grows linearly with the number of antennas. To give you an idea, the number of antennas on a single base station has increased from a maximum of 8 in 4G LTE to over 100 in 5G deployments. More antennas mean a much bigger map, and a bigger map means more information to send back. This creates a huge feedback overhead, and our work is all about finding a smarter way to reduce this overhead.
Our idea: user-driven, adaptive feedback
To tackle this challenge we propose a user-driven feedback method that adapts on the fly. This means users can send a super-detailed map, or just a quick, rough sketch to save bandwidth. Most importantly, it all works seamlessly with existing CSI autoencoders and doesn’t require any major system changes.
At its core, our approach combines two key components:
- a nested dropout (ND) layer (Rippel et al., 2014), which is a clever way of organizing the data. Think of it like a priority list—the most important information is always at the top, and the less critical details follow.
- a vector quantization (VQ) layer, which then takes that prioritized data and efficiently encodes it.
Together, these two components enable flexible and efficient CSI feedback, and we call our approach ordered vector quantization (OVQ).
How it works
So, how exactly does our method create a flexible, user-driven system? It all comes down to a clever two-step process.
First, an encoder network takes the input CSI and turns it into a long vector, which we’ll call $\vz$. Instead of trying to quantize this entire vector, we reshape it into a matrix. This transformation is key because it allows us to quantize several smaller vectors instead of one huge one. This keeps the codebook size manageable and facilitates the learning process.
The real magic happens here: we use a ND layer that imposes an ordering on these smaller vectors. During training, the model is forced to prioritize the most important information in the first few vectors, as they are always available for reconstruction. The later vectors then act as refinements, adding more detail.
Next, a VQ layer maps each of these prioritized vectors to the closest codeword from a shared codebook. This ensures the feedback can be represented with a specific number of bits per vector.
The benefit of this ordered system is that each user can choose how many vectors to send back, depending on their bit budget:
- Fewer vectors $\rightarrow$ shorter feedback, coarser reconstruction.
- More vectors $\rightarrow$ longer feedback, higher accuracy.
The proposed scheme is illustrated in Figure 1 below.
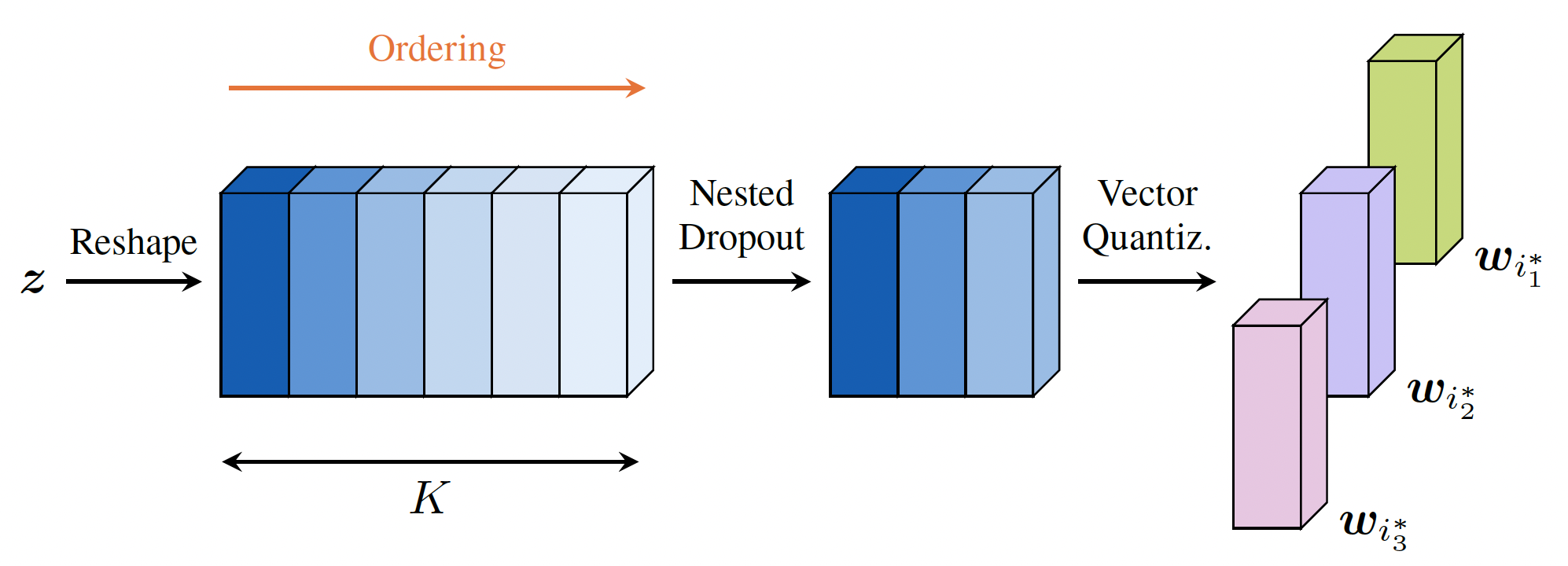 User-driven ordered vector quantization feedback scheme.
User-driven ordered vector quantization feedback scheme.
Training in two steps
To make this all work, we train our model in two stages:
Pretraining (without ND layer): We first pretrain the model using a standard VQ-VAE objective (van den Oord et al., 2017) to build a reliable codebook, which serves as the shared dictionary for compression.
Fine-tuning (with ND layer): In this phase, we introduce the ND layer while continuing to train the entire model, including the codebook. The network trains by averaging over all possible truncation lengths. This teaches the network to prioritize the most important details, so that the ability to send ordered, variable-length feedback emerges naturally.
Results
We simulated our method on both indoor and outdoor datasets (Wen et al., 2018). In Figure 2, we show the results by measuring the normalized mean squared error (NMSE), which tells us how accurate our reconstructed CSI is, against the bit budget ($B$) we have to work with. For our tests, we used CRNet (Lu et al., 2020) as base autoencoder model, though our paper also explores its performance with other autoencoders.
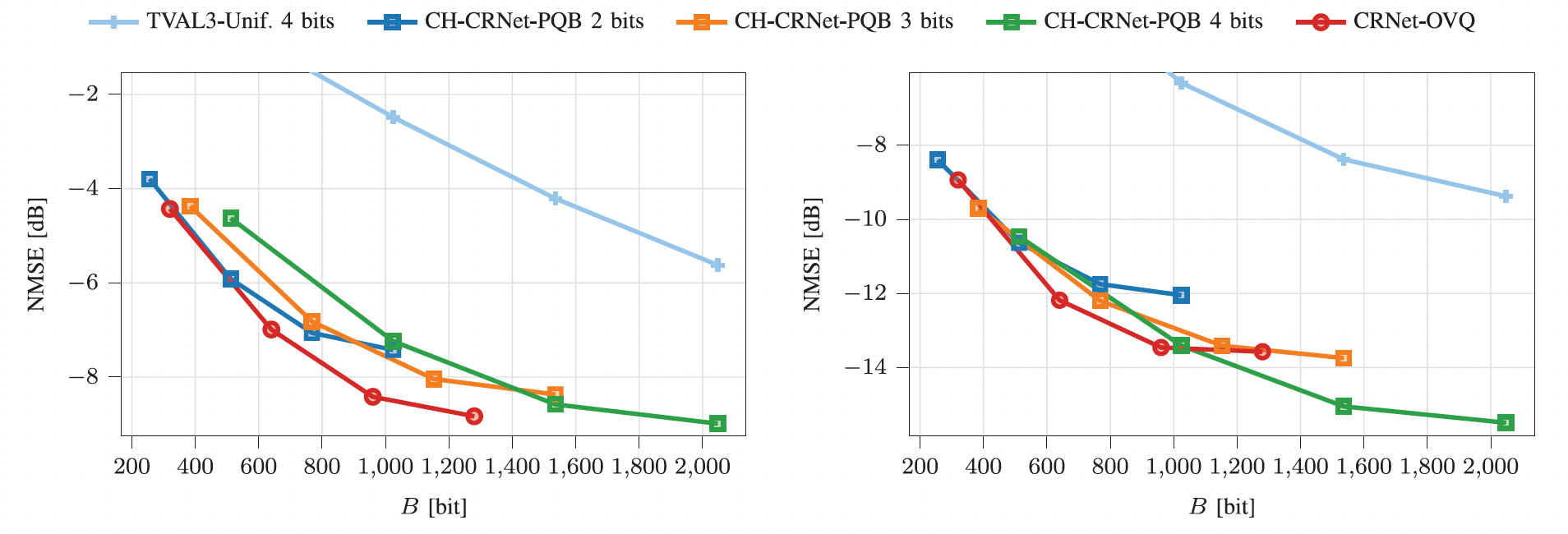 NMSE for the COST2100 outdoor (left) and indoor (right) datasets.
NMSE for the COST2100 outdoor (left) and indoor (right) datasets.
What’s really cool is how our method, OVQ, performs on the outdoor dataset. It not only adapts across different bit budgets, but it actually beats other methods while using fewer bits.
When we look at the indoor scenario, the story is a bit different. Our method’s advantage isn’t as strong in the low-bit region. Additionally, we can see that a competing method, CH-PQB with 4 bits, has an advantage in the high-bit region. This indicates that for this scenario, alternative methods can provide higher accuracy when the bit budget is sufficiently high.
Why does this matter?
![]() Ultimately, what our research shows is that we can be smarter about what we send back. As wireless systems continue to scale up with more antennas and users, flexible and efficient feedback schemes like OVQ could be key to making massive MIMO more practical in real-world networks.
Ultimately, what our research shows is that we can be smarter about what we send back. As wireless systems continue to scale up with more antennas and users, flexible and efficient feedback schemes like OVQ could be key to making massive MIMO more practical in real-world networks.
References
- Rizzello, V., Nerini, M., Joham, M., Clerckx, B., & Utschick, W. (2023). User-Driven Adaptive CSI Feedback With Ordered Vector Quantization. IEEE Wireless Communications Letters, 12(11), 1956–1960. https://doi.org/10.1109/LWC.2023.3301992
- Rippel, O., Gelbart, M., & Adams, R. (2014). Learning Ordered Representations with Nested Dropout. 31st International Conference on Machine Learning, ICML 2014, 5.
- van den Oord, A., Vinyals, O., & kavukcuoglu, koray. (2017). Neural Discrete Representation Learning. Advances in Neural Information Processing Systems, 30.
- Wen, C.-K., Shih, W.-T., & Jin, S. (2018). Deep Learning for Massive MIMO CSI Feedback. IEEE Wireless Communications Letters, 7(5), 748–751. https://doi.org/10.1109/LWC.2018.2818160
- Lu, Z., Wang, J., & Song, J. (2020). Multi-resolution CSI Feedback with Deep Learning in Massive MIMO System. ICC 2020 - 2020 IEEE International Conference on Communications (ICC), 1–6. https://doi.org/10.1109/ICC40277.2020.9149229
Frequency division duplexing is a communication technique that uses separate frequency bands for simultaneous uplink (from user to base station) and downlink (from base station to user) transmissions. ↩